Essential Concepts for PostgreSQL
Chapter 2: Building blocks, Keys, Indexes and DataTypes



Table of contents
- Understanding the Building Blocks: Tables, Rows, and Columns
- Setup your DB for the Next Steps
- The Power of Primary Keys and Indexes
- Navigating PostgreSQL's Data Types and Their Use Cases
- Practising SQL Basics: SELECT, INSERT, UPDATE, DELETE
- TLDR;
- What's next
This is Chapter 2 of the series PostgreSQL Distilled, where I teach only the most important parts of PostgreSQL to aspiring Fullstack Engineers.
Here is the Chapter 1: Getting Started with PostgreSQL
Understanding the Building Blocks: Tables, Rows, and Columns
When it comes to databases, especially in PostgreSQL, as we've begun exploring in Chapter 1, the basic building blocks are tables, rows, and columns.
To truly grasp these concepts, we'll break them down one by one.
Tables: The Framework of Data Storage
A table is a collection of related data organized within a database. Think of a table as a neatly structured grid, like a spreadsheet. It's a space where you can store information about a specific topic, such as employees in a company.
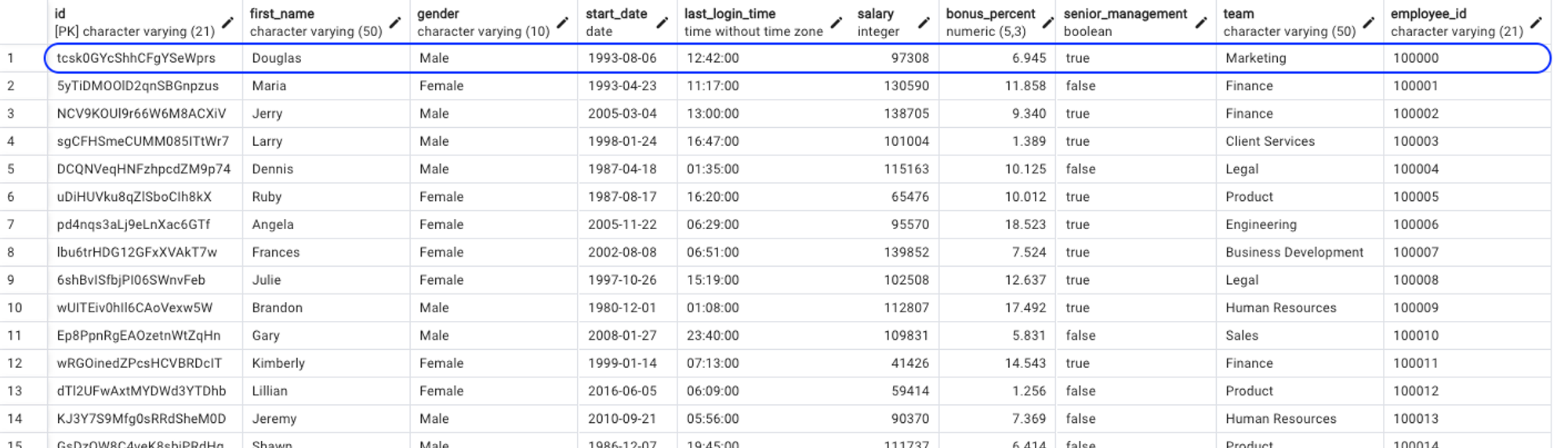
In our ongoing exploration, we're working with an employees table. This table is designed to hold all the information about employees in a particular organization.
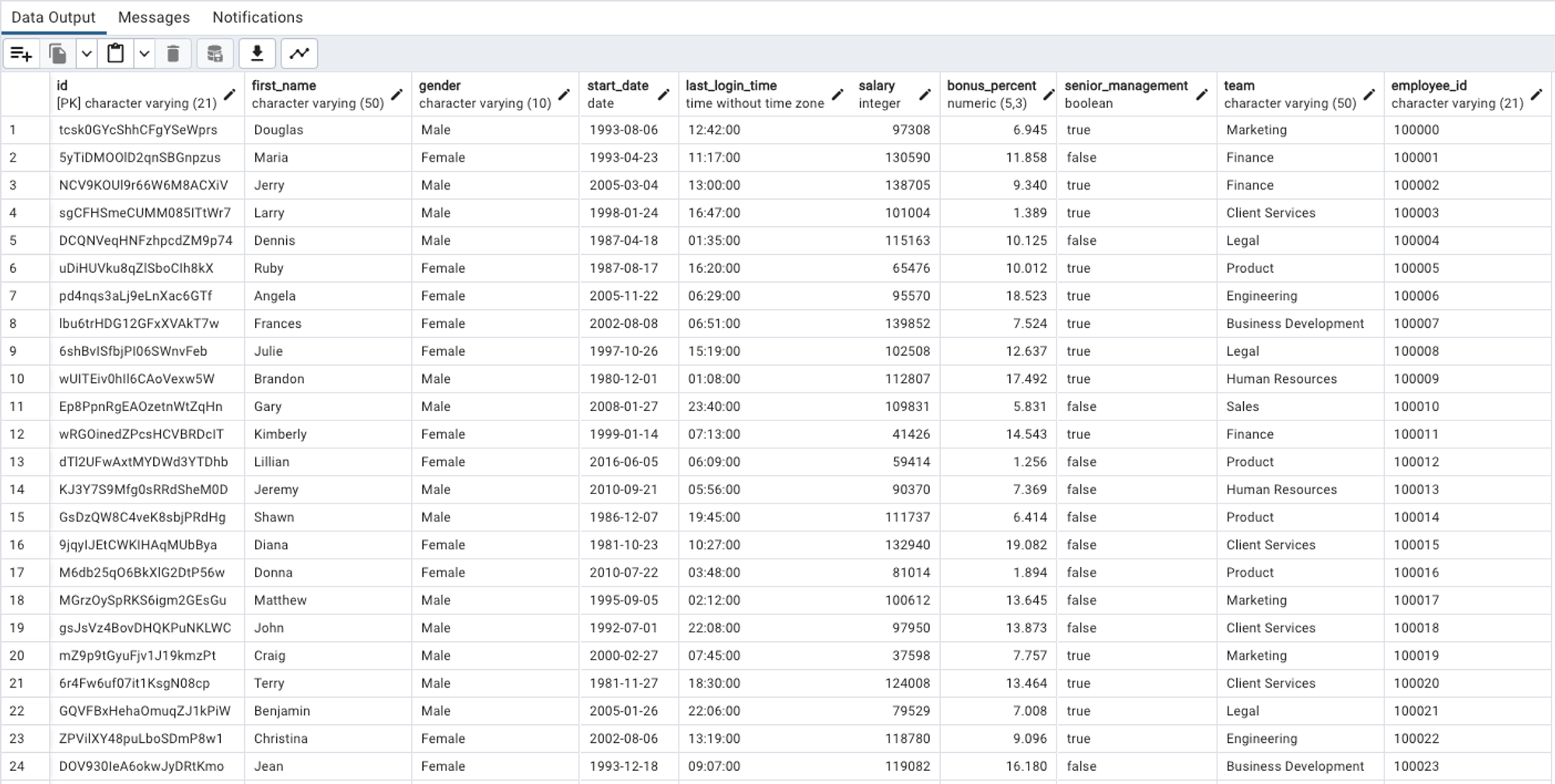
Columns: Defining the Characteristics
Columns in a table define what kind of information will be stored. Each column has a unique name and a specific data type, which sets the rules for the data that can be stored in that column.
In the employees table, here are some of the columns:
id: The unique identifier for each employee.first_name: The first name of the employee.gender: The gender of the employee.start_date: The date the employee started working.
CREATE TABLE employees (
id VARCHAR(21) PRIMARY KEY,
first_name VARCHAR(50),
gender VARCHAR(10),
start_date DATE,
...
);
These columns provide structure and enforce consistency within the data.
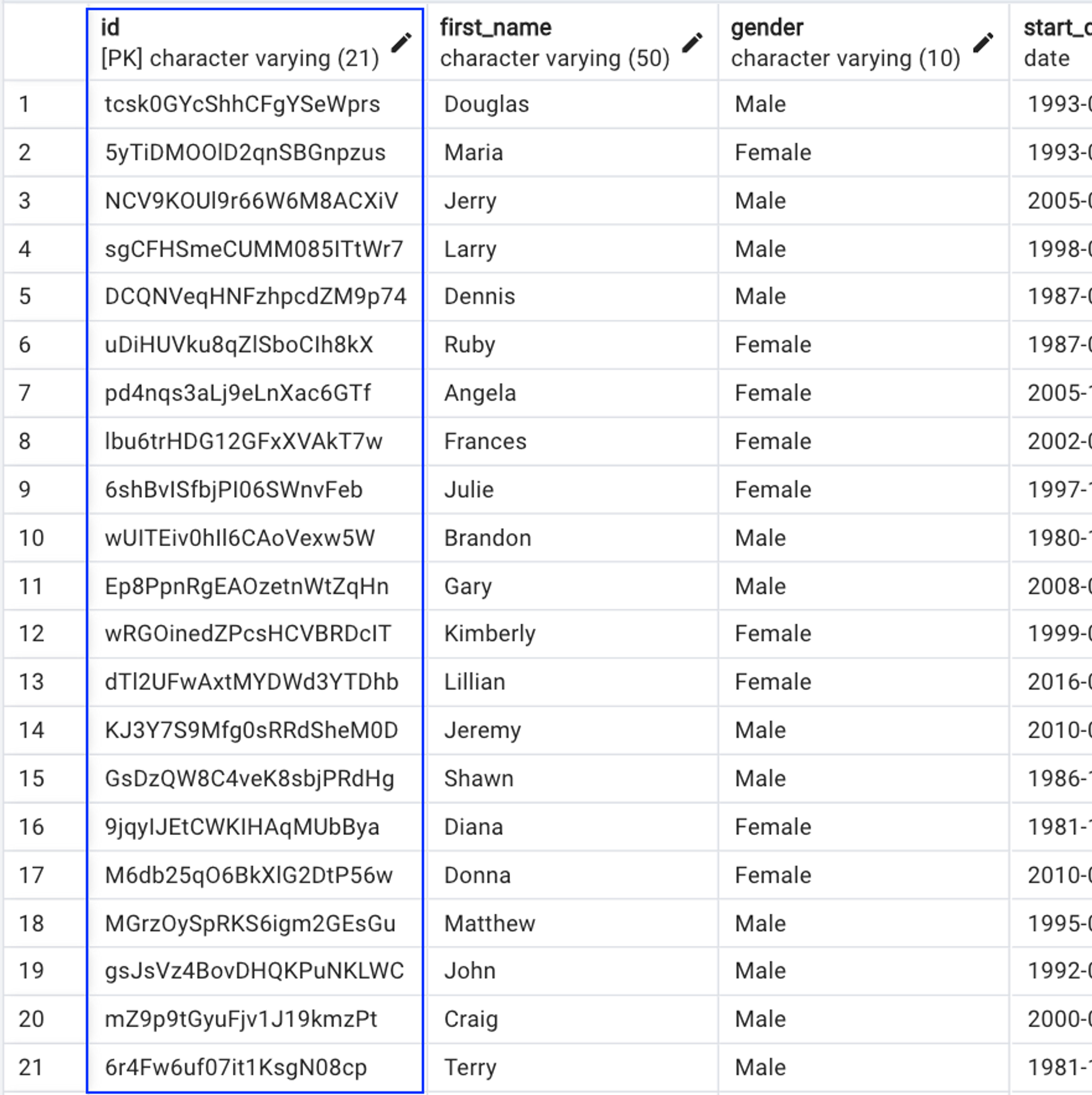
Rows: Individual Entries of Data
Rows are the individual records within a table. Each row contains a unique set of data, corresponding to the columns defined in the table.
Imagine each row in the employees table as different employees. The id column will contain that employee's unique ID, the first_name column will contain their first name, and so on.
For example, a row might look like this:
id: '12345'first_name: 'John'gender: 'Male'start_date: '2022-08-17'
Types of Tables in PostgreSQL
Imagine a rapidly growing tech company, TechCorp, that needs to build a robust HR System to manage its expanding workforce.
The HR System must handle various aspects such as employee details, temporary analysis, fast data processing, historical data, and remote data access.
Let's see how different types of PostgreSQL tables can be utilized to meet these requirements.
1. Regular Tables: Storing Employee Details
Requirement: TechCorp needs to store detailed information about its employees, including their names, salaries, positions, and departments.
Solution: Regular tables can be used to store this structured data.
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
salary DECIMAL(10, 2),
position VARCHAR(30),
department VARCHAR(30)
);
2. Temporary Tables: Conducting Temporary Analysis
Requirement: The HR team often conducts temporary analysis on employee performance and needs a place to store this transient data.
Solution: Temporary tables are perfect for this purpose.
CREATE TEMP TABLE temp_performance AS
SELECT * FROM employees WHERE performance_rating > 8;
3. Unlogged Tables: Fast Data Processing
Requirement: TechCorp's HR System requires real-time processing of attendance data, and speed is crucial.
Solution: Unlogged tables, which skip Write-Ahead Logging, can be used for fast data processing.
CREATE UNLOGGED TABLE attendance (
id SERIAL PRIMARY KEY,
employee_id INT,
date DATE,
status VARCHAR(10)
);
4. Partitioned Tables: Managing Historical Data
Requirement: The company wants to maintain historical records of employee promotions and salary changes.
Solution: Partitioned tables can be used to divide this large dataset into manageable pieces.
CREATE TABLE promotions (
promotion_id SERIAL PRIMARY KEY,
employee_id INT,
promotion_date DATE,
new_position VARCHAR(30)
) PARTITION BY RANGE (promotion_date);
CREATE TABLE promotions_2021 PARTITION OF promotions FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
5. Foreign Tables: Accessing Remote Data
Requirement: TechCorp has a subsidiary company, and the HR System needs to access employee data from the subsidiary's remote database.
Solution: Foreign tables enable this remote data access.
CREATE EXTENSION postgres_fdw;
CREATE SERVER remote_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'remote-host', dbname 'remote-db');
CREATE FOREIGN TABLE remote_employees (
id INT PRIMARY KEY,
name VARCHAR(50)
) SERVER remote_server;
Summation
The real power of tables, rows, and columns comes when you understand how they interconnect. A table like employees is not just a random collection of data; it's a meticulously structured arrangement that allows for efficient querying, updating, and management of information.
If a database is a library, then tables are the shelves, columns are the different sections of each shelf, and rows are the individual books. Together, they allow the librarian (that's you, the database manager) to find exactly what's needed, quickly and efficiently.
As we continue to explore more complex concepts they are the foundation on which everything else is built.
Everything that we will learn about PostgreSQL will be around how to put and retrieve data from these tables.
Setup your DB for the Next Steps
Let’s set up our DB that we need to follow along:
Step 1: Create the Necessary Tables
Initiate your adventurous exploration by executing this specific SQL query in your PgAdmin Query Tool for the HR Department Database. This script will build the structural framework of our database, laying the groundwork for our real-world examples.
Link : SQL Query for Table Creation - Chapter 02
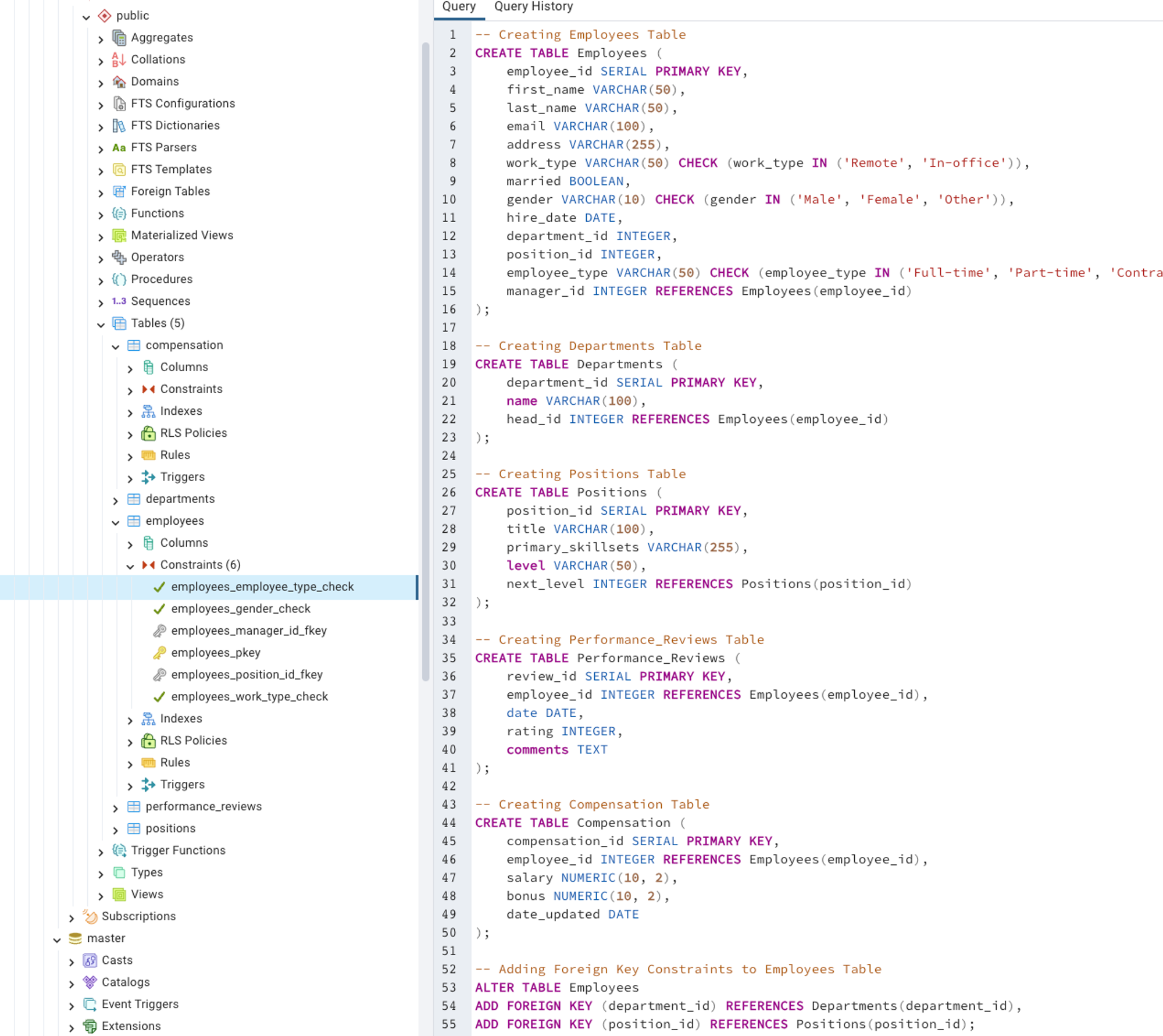
Step 2: Inject Life with Data
Import all the data from these folders to breathe life into our tables.
The information will mirror the intricacies of a real-world HR Department, enriching our learning experience.
You can use the PgAdmin tool to import the datasets as shown in the previous chapter or from here
Link: Mock Data for Chapter 02
A Simple Challenge
Don’t ignore this
You're most likely to stumble upon an obstacle while uploading the data. Fear not, for this challenge is by design.
Hint: Your path may be blocked by a foreign key CONSTRAINT. Examine the object explorer closely, and you'll find the key to unlock the door.
I want you to figure out the reason, analyze the obstacle, and triumph over it. In the world of databases, problems are puzzles, and solutions are achievements share on Twitter / X using #pgdistilled and tag me in your post.
Hint:
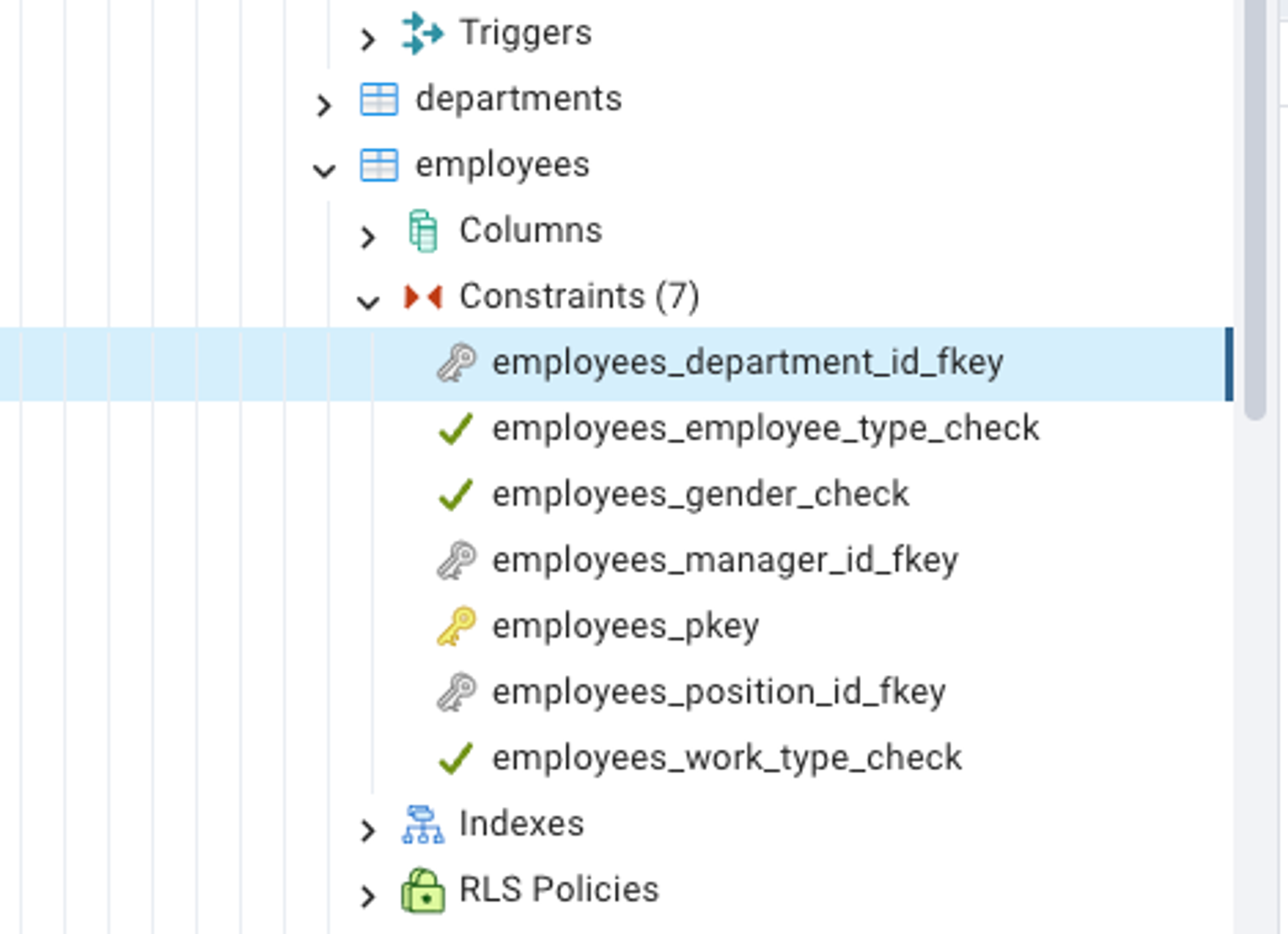
Link: Stack Overflow
Summation
By following these steps, you have not only set up a database but engaged in a journey filled with learning, exploration, and triumph. It's more than technical execution; it's a metaphor for the real-world challenges you'll conquer in your career to handle databases.
Now, with the database ready, our adventure in understanding PostgreSQL continues!
The Power of Primary Keys and Indexes
In the world of databases, primary keys and indexes are the most important ideas.
They are the linchpins holding the structure together, ensuring data integrity, and optimizing access paths.
Indexing is a major strategy for the performance optimisation of the database and we’ll cover that in the eighth chapter in greater detail.
Now, using our HR Department's database, we will delve into the power of these essential components.
Understanding Primary Keys
What is a Primary Key?
A primary key is a specific field or a combination of fields that uniquely identify a record within a table. It's like the unique employee ID in a corporation; no two employees can have the same ID.
The Importance of Primary Keys
Uniqueness: Ensures that no two records have the same primary key value.
Data Integrity: By maintaining uniqueness, primary keys prevent accidental duplication.
Relationships: Facilitates the creation of relationships between tables through foreign key constraints.
Example from Our HR Database:
In our employees table, the field employee_id is the primary key. It uniquely identifies each employee.
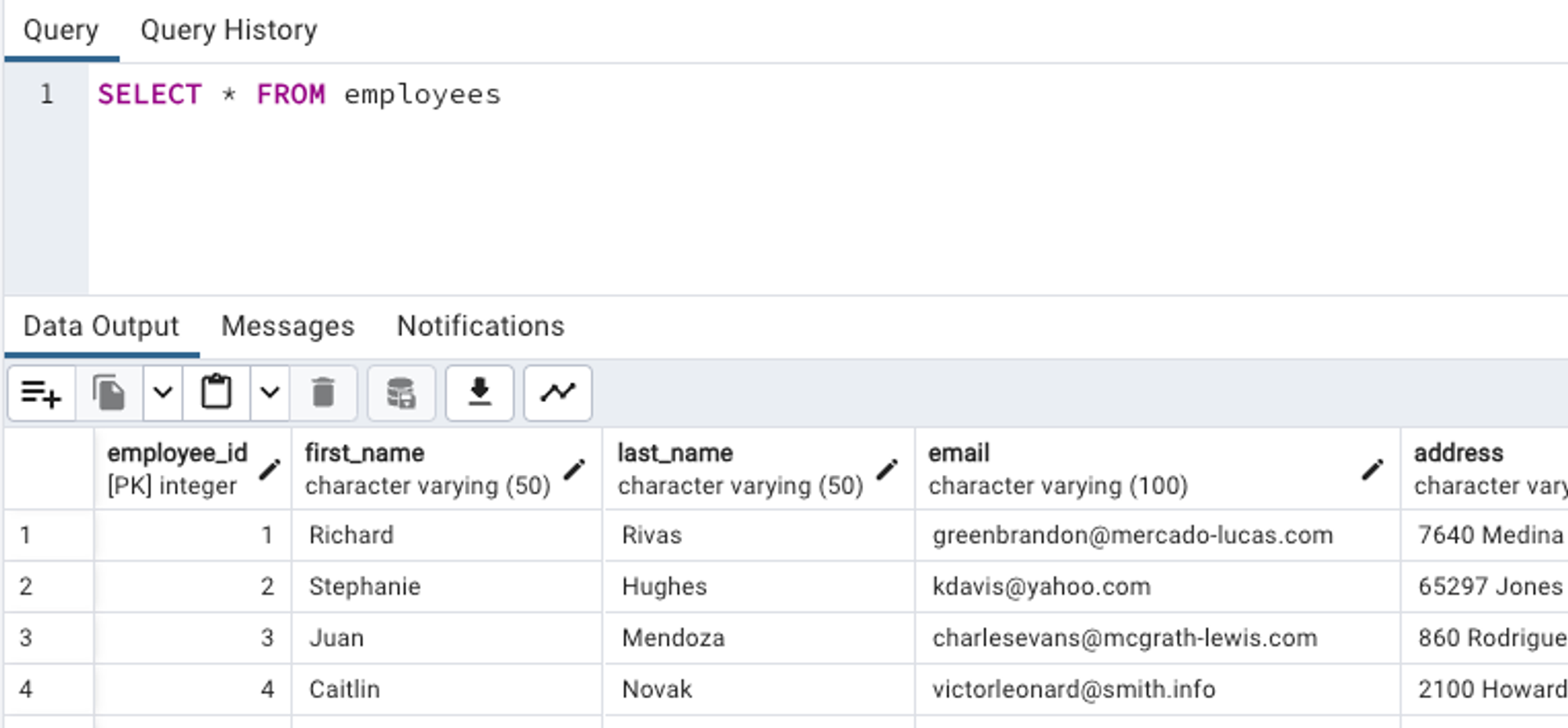
More keys in PostgreSQL
There are other keys in SQL that are important when you design large-scale databases.
Candidate Key
Super Key
Foreign Key
Composite Key
Alternate Key
Unique Key
You can use this below prompt in ChatGPT to learn about them
Prompt #1:
Roleplay a Senior Engineer who is an expert in PostgreSQL and verbose while explaining
With 10+ years of experience you are now asked to teach the basic of SQL to the new hires or less experienced colleagues.
You're teaching them about these topics
Primary Key
Candidate Key
Super Key
Foreign Key
Composite Key
Alternate Key
Unique Key
Can you explain them with real world examples?
Prompt #2:
Let's dive into super key/candidate key and create a dummy table and query to explain the idea
Indexes
Unindexed vs. Indexed Queries
Imagine you're in a vast library filled with shelves of data. You're searching for a specific piece of information, and it feels like searching for a needle in a haystack.
Let's take our employees table:
CREATE TABLE employees (
employee_id integer,
first_name varchar,
last_name varchar,
...
);
When you run a query like:
SELECT first_name FROM employees WHERE employee_id = constant;
Without an index on the employee_id column, your database would be like a reader without a guide, having to scan every page (row) in the employees table to find the desired data. A monumental task, indeed!
With Index: The Guided Path
But what if we give our reader a map?
By creating an index on the employee_id column, we're building a pathway to the information, like a book's index guiding a reader to the right pages.
The search becomes:
CREATE INDEX employees_id_index ON employees (employee_id);
The name employees_id_index is like the title of the chapter – choose something that resonates with the purpose of the index.
With this, our database no longer roams through the employees table. It quickly navigates to the desired data, just like scanning an alphabetic index at the end of a book.
The Power of Index: Dynamic and Versatile
Indexes are like living pathways, evolving with your data. Once created, they automatically update with the table modifications, breathing alongside your data's rhythm.
Need to remove an index? Use the DROP INDEX command, like pruning a branch that's no longer needed.
And it's not just about searching. Indexes fuel UPDATE and DELETE commands, and they accelerate join searches too. They're the jet engines to your queries, propelling them to the right destinations at breakneck speed.
Remember to run the ANALYZE command regularly. It's like fine-tuning your navigation system, helping the query planner make well-informed decisions.
You'll learn more about this in Chapter 8.
Dig Deeper
- Now that you have a basic understanding of what it is, delve into the documentation to read even further.
You can explore all the strategies of indexing in PostgreSQL using this mindmap
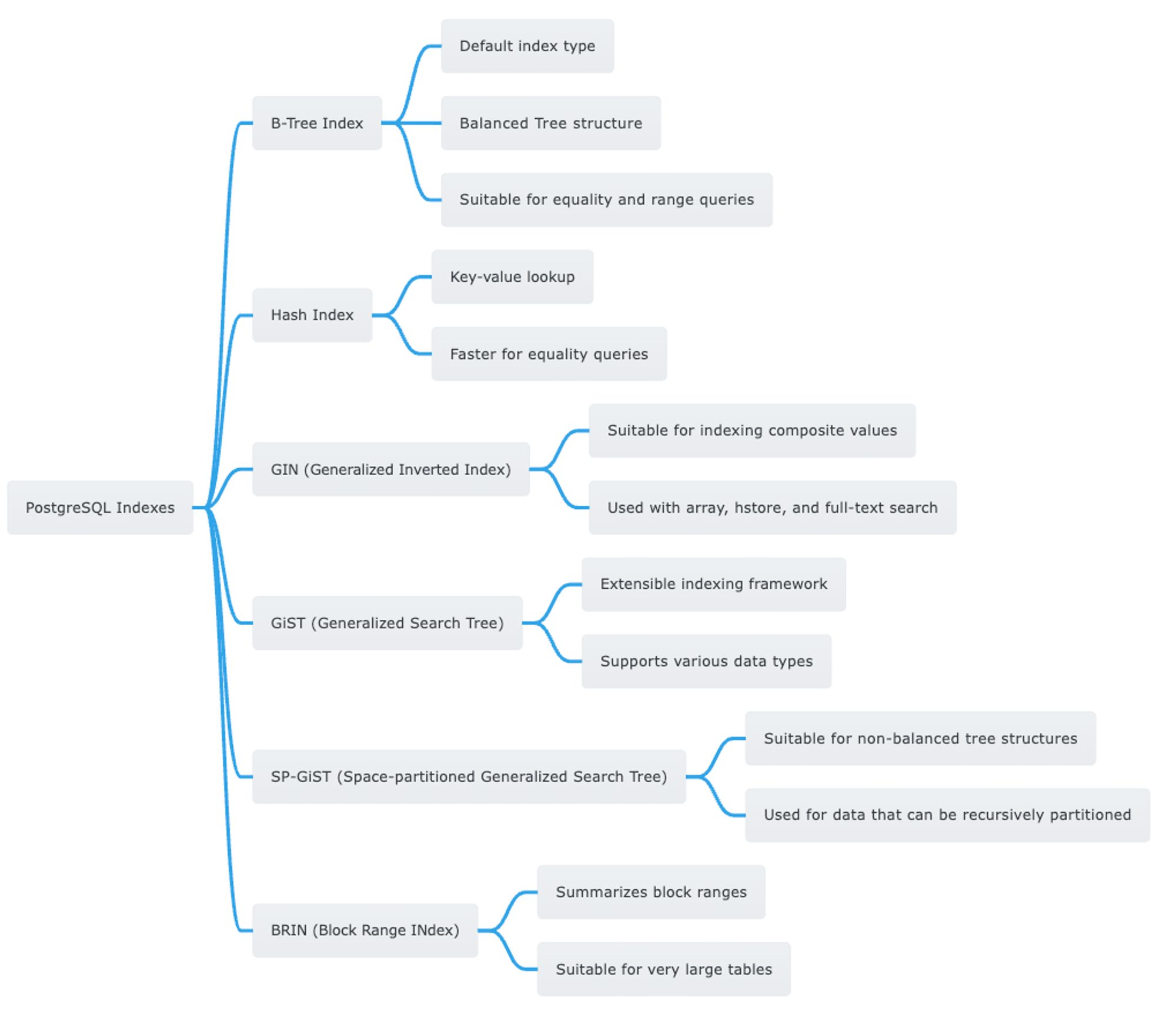
Navigating PostgreSQL's Data Types and Their Use Cases
A glance of all the data types and their subtypes used in PostgreSQL
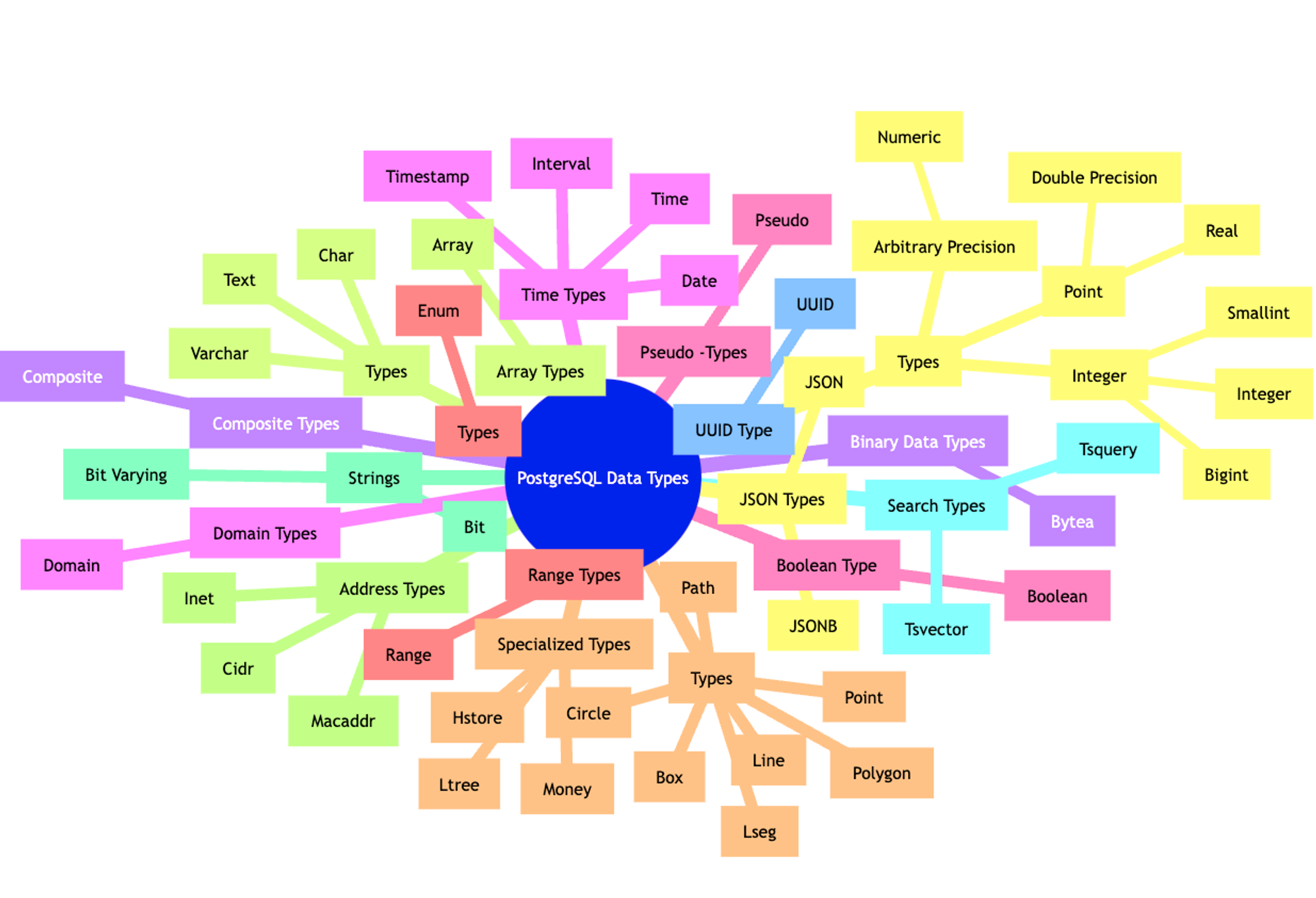
If you are now overwhelmed let's learn 20% of the most important data types that will help you achieve 80% of the use cases.
1. Numeric Types
a. Integer
Smallint: Used for small ranges, such as age, rating, etc.
Integer: Commonly used for IDs, quantities, counts, etc.
Bigint: Used for very large numbers, like population, views, etc.
b. Floating-Point
Real: Suitable for scientific calculations, measurements, etc.
Double Precision: Used for precise calculations, financial data, etc.
c. Arbitrary Precision
- Numeric: Ideal for monetary values, exact arithmetic, etc.
2. Character Types
a. Character Varying (Varchar)
- Used for names, addresses, emails, etc.
b. Text
- Suitable for long texts, comments, descriptions, etc.
3. Date/Time Types
a. Timestamp
- Used for recording events, logging, tracking changes, etc.
b. Date
- Suitable for birthdates, anniversaries, deadlines, etc.
c. Time
- Used for scheduling, opening hours, etc.
4. Boolean Type
- Boolean: Ideal for flags, status (active/inactive), etc.
5. Binary Data Types
a. Bytea
- Used for storing binary data like images, files, etc.
6. UUID Type
- UUID: Suitable for unique identifiers across distributed systems, etc.
Example: Employee Table
Here's an example of an employee table that utilizes all the above data types:
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age SMALLINT,
salary NUMERIC(10, 2),
is_manager BOOLEAN,
hire_date DATE,
last_login TIMESTAMP,
profile_picture BYTEA,
precise_rating DOUBLE PRECISION,
unique_token UUID
);
Understanding the specific use cases for each data type helps in designing efficient and meaningful database schemas.
By selecting the appropriate data types for each field, developers can ensure data integrity, optimize storage, and enhance query performance.
Whether you're designing a simple application or a complex system, these core PostgreSQL data types are the building blocks that will support your data needs.
Dig Deeper
Official Docs: https://www.postgresql.org/docs/current/datatype.html
Practising SQL Basics: SELECT, INSERT, UPDATE, DELETE
SELECT, INSERT, UPDATE, and DELETE: Let's explore these keywords and then provide some practice questions to hone your skills.
1. SELECT
The SELECT statement is used to query data from one or more tables in the database. You can specify the columns you want to retrieve and apply various conditions to filter the results.
Example:
SELECT first_name, last_name FROM employees WHERE work_type = "Remote";
2. INSERT
The INSERT statement is used to add new rows to a table. You can specify the values for each column or use a subquery to insert data from another table.
Example:
INSERT INTO employees (first_name, last_name, age) VALUES ('John', 'Doe', 25);
3. UPDATE
The UPDATE statement is used to modify existing data in a table. You can change the values of one or more columns based on specific conditions.
Example:
UPDATE compensation SET salary = salary * 1.10 WHERE bonus > 100;
4. DELETE
The DELETE statement is used to remove rows from a table. You can delete all rows or apply conditions to delete specific records.
Example:
DELETE FROM employees WHERE hire_data < 2015-12-12;
Practice Questions
Easy: Write a SELECT query to retrieve all the employee names and ages from the "employees" table.
Intermediate: Write an INSERT query to add a new employee to the "employees" table with the following details: First Name - "Jane", Last Name - "Smith", Age - 28.
Intermediate: Write an UPDATE query to increase the salary of all employees who are managers (is_manager = TRUE) by 5%.
Advanced: Write a DELETE query to remove all employees who have not logged in since the year 2021.
Advanced: Write a SELECT query to retrieve the first name, last name, and salary of the top 5 highest-paid employees, ordered by salary in descending order.
Summation
Understanding and practising the basic SQL operations of SELECT, INSERT, UPDATE, and DELETE is foundational for anyone working with relational databases.
These commands allow you to retrieve, add, modify, and delete data, providing the flexibility to manage and analyze information effectively.
Don’t skip unless you want half-baked knowledge for your career.
TLDR;
Pheww!! Congratulations on making it this far. Here's a quick look at what we have learnt
Here's a concise summary for those looking to get the core insights quickly:
The Building Blocks: Tables, rows, and columns are the foundation of PostgreSQL databases. They align together to store and organize data effectively.
Setting up your Database: Here we set up your entire database to follow along with the advanced concepts that are coming in the future blogs.
Primary Keys & Indexes: They are the guiding stars and the fast tracks of the database. Primary keys uniquely identify records, while indexes speed up searches, just like an index in a book.
Data Types: PostgreSQL's various data types are the colours of our data canvas. From integers to JSON, each type serves a unique purpose, helping to shape the data landscape.
SQL Basics: The brush strokes of database management. SELECT retrieves data, INSERT adds it, UPDATE modifies, and DELETE removes. Mastery of these commands empowers control over the database.
What's next
I am writing this series on PostgreSQL to teach frontend engineers full-stack engineering.
The next chapter is Chapter 3: The way of PostgreSQL
So, make sure to follow me on X/ Twitter sagar_codes to learn full-stack engineering.