PostgreSQL Distilled: The way of Postgres
Chapter 3: Constructs, CTEs and Lateral Join



Chapter 3: The Way of PostgreSQL
Introduction
So, we have learnt the basic and essential concepts of PostgreSQL in Chapter 1 and Chapter 2
Now, let's delve a little deeper to know some of the cooler, more advanced stuff that’d be helpful for you while using PostgreSQL.
We're going to explore some nifty PostgreSQL features: things like views, some handy SQL constructions, Common Table Expressions (CTEs) and lateral joins.
By the time you wrap up this chapter, you'll know a bunch of pretty advanced stuff that will help you in 80% of development work.
You'll understand when and how to use these advanced features, making your SQL queries more efficient and, honestly, more impressive.
One thing you’d notice, PostgreSQL strictly follows ANSI SQL and if you’re confident with ANSI SQL you are good to start
If you’re completely new to SQL or looking for a quick refresher this guide is for you.
Let’s dive in.
Constructions in PostgreSQL
Before we start talking about the different types of constructions that are present in PgSQL let’s talk about what are constructions.
If you are familiar with Java or JavaScript you would have used in-built functions that help us in our day-to-day code. Similarly, in SQL these functions are called Constructions.
That’s it, that’s the basic idea behind construction.
Some constructions that you are already familiar with are DISTINCT or LIKE etc.
So now we are going to look into some constructions that are offered by PostgreSQL:
DISTINCT ON
What is it?
DISTINCT ON is a PostgreSQL-specific feature that returns the first row of each set of rows grouped by some columns.
Where to use it in our database?
If you want to get a unique list of employees based on, say, their work_type and only see the first employee of each work type, you'd use DISTINCT ON.
SELECT DISTINCT ON (work_type) * FROM employees ORDER BY work_type, hire_date;
LIMIT AND OFFSET
What is it?
These commands restrict the number of rows returned. LIMIT determines the maximum number of rows to return, while OFFSET skips a certain number of rows before beginning to return rows.
Where to use it in our database?
To get the first 10 employees, skipping the initial 5
SELECT * FROM employees LIMIT 10 OFFSET 5;
Shorthand Casting
What is it?
Converts one data type to another. In PostgreSQL, you can use the :: shorthand to cast data types.
Where to use it in our database?
If you wanted to convert the salary in the compensation table from numeric to text:
SELECT salary::text FROM compensation;
Multirow Insert
What is it?
Allows you to insert multiple rows into a table in a single INSERT statement.
Where to use it in our database?
INSERT INTO employees (first_name, last_name) VALUES ('John', 'Doe'), ('Jane', 'Smith'), ('Alice', 'Brown');
Sure, here is the provided information formatted properly for a word editor:
ILIKE
What is it?
The ILIKE operator is a case-insensitive version of the LIKE operator.
Where to use it in our database?
To find all employees with names that contain 'john', irrespective of case:
SELECT * FROM employees WHERE first_name ILIKE '%john%';
Returning Functions
What is it?
After an INSERT, UPDATE, or DELETE, the RETURNING clause returns the rows affected.
Where to use it in our database?
When updating an employee's address and wanting to see the changes:
UPDATE employees SET address = '123 New St' WHERE employee_id = 1 RETURNING *;
DO
What is it?
Executes an anonymous code block, useful for running procedural code without defining a function.
Where to use it in our database?
To increment every employee's salary in the compensation table by 10%:
DO $$
BEGIN
UPDATE compensation SET salary = salary * 1.10;
END
$$;
FILTER
What is it?
In aggregate functions, the FILTER clause allows you to aggregate only a subset of rows.
Where to use it in our database?
To find the average salary of married employees:
SELECT AVG(salary) FILTER (WHERE married = true) FROM compensation;
ARRAY types and operations
What is it?
PostgreSQL allows you to define columns as array types, which can store multiple values in a single column. Plus, it provides a rich set of operators for working with these arrays.
Where to use it?
Say, if an employee had multiple phone numbers:
ALTER TABLE employees ADD COLUMN phone_numbers text[];
UPDATE employees SET phone_numbers = ARRAY['123-456-7890', '234-567-8901'] WHERE employee_id = 2;
WINDOW FUNCTION
What is it?
By definition, a window function performs a calculation across a set of table rows that are somehow related to the current row.
Where to use it in our database?
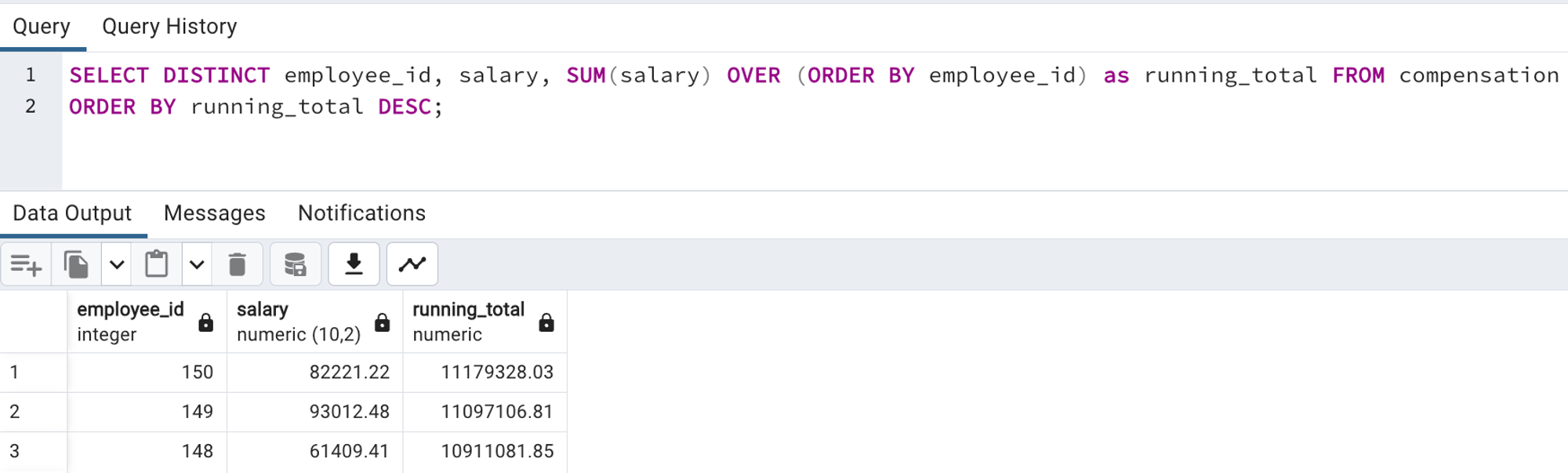
If you want to perform any operation on the rows of the current table you can use a WINDOW FUNCTION. For example here in the below code, we are calculating the SUM of salary for each employee and aggregating on the running_total column. So at the end of the table, we’ll have the total compensation of the company.
SELECT DISTINCT employee_id, salary, SUM(salary) OVER (ORDER BY employee_id) as running_total FROM compensation
ORDER BY running_total DESC;
Here is a list of commonly used window functions in PostgreSQL:
ROW_NUMBER(): Assigns a unique integer value to each row within a result set, based on the specified ordering.
RANK(): Assigns a unique rank to each distinct row within a result set. Rows with equal values receive the same rank, and the next rank is skipped.
DENSE_RANK(): Similar to RANK(), but without skipping rank numbers for equal values. Consecutive rows with equal values receive consecutive dense ranks.
FIRST_VALUE(expression): Returns the value of a specified expression from the first row within the partition.
LAST_VALUE(expression): Returns the value of a specified expression from the last row within the partition.
PERCENTILE_CONT(fraction) WITHIN GROUP (ORDER BY expression): Calculates the value at the specified percentile for a given expression within the partition.
PERCENTILE_DISC(fraction) WITHIN GROUP (ORDER BY expression): Returns the value at the specified percentile using discrete values within the partition.
SUM(expression) OVER (PARTITION BY partition_column ORDER BY order_column): Computes the cumulative sum of a specified expression within the partition, based on the specified order.
AVG(expression) OVER (PARTITION BY partition_column ORDER BY order_column): Calculates the cumulative average of a specified expression within the partition, based on the specified order.
MIN(expression) OVER (PARTITION BY partition_column ORDER BY order_column): Retrieves the minimum value of a specified expression within the partition, based on the specified order.
MAX(expression) OVER (PARTITION BY partition_column ORDER BY order_column): Retrieves the maximum value of a specified expression within the partition, based on the specified order.
COUNT(*) OVER (PARTITION BY partition_column ORDER BY order_column): Computes the cumulative count of rows within the partition, based on the specified order.
Read further here
PARTITION BY
What is it?
Used with window functions, it divides the result set into partitions to perform calculations across them.
Where to use it in our database?
To get the highest salary within each work_type:
SELECT
e.first_name,
e.last_name,
d.name AS department_name,
c.salary,
AVG(c.salary) OVER (PARTITION BY e.department_id) as average_department_salary
FROM
employees e
JOIN
compensation c ON e.employee_id = c.employee_id
JOIN
departments d ON e.department_id = d.department_id;
That brings us to the end of this section where we reviewed all the common Constructions of PostgreSQL.
If you are comfortable with these constructs 80% of your work using PostgreSQL should be covered.
Now let's learn another common concept of Postgres that you're likely to encounter multiple times in your projects.
Common Table Expression ( CTEs )
What is CTE?
Think of CTEs like a temporary staging table within a single query. For instance, if you wanted to first gather a subset of employees from the employees table based on certain criteria and then perform some operation on this subset, a CTE can help.
Example: Let's say we want to fetch all employees with their corresponding salary details.
WITH EmployeeSalaries AS (
SELECT e.first_name, e.last_name, c.salary
FROM employees e
JOIN compensation c ON e.employee_id = c.employee_id
)
SELECT * FROM EmployeeSalaries;
What Problem Does It Solve?
CTEs make complex queries more readable by breaking them down.
Example: Let's find the average salary of employees working in the 'HR' department.
WITH HREmployees AS (
SELECT e.employee_id, c.salary
FROM employees e
JOIN compensation c ON e.employee_id = c.employee_id
WHERE department_id = (SELECT department_id FROM departments WHERE name = 'HR')
)
SELECT AVG(salary) FROM HREmployees;
Where to Use It?
Hierarchical Data: Recursive CTEs are excellent for this.
Simplifying Queries Formation
If you want a simplified view of your query and form complex queries a CTE is a must.
Example: To list out each employee and their manager:
WITH RECURSIVE EmployeeHierarchy AS (
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.employee_id, e.first_name, e.last_name, e.manager_id
FROM employees e
JOIN EmployeeHierarchy eh ON e.manager_id = eh.employee_id
)
SELECT * FROM EmployeeHierarchy;
Intermediate Computations: When you need to compute something in between.
Example: Finding the total compensation (salary + bonus) for employees:
WITH TotalCompensation AS (
SELECT employee_id, (salary + bonus) AS total_compensation
FROM compensation
)
SELECT e.first_name, e.last_name, tc.total_compensation
FROM employees e
JOIN TotalCompensation tc ON e.employee_id = tc.employee_id;
Where Not to Use It?
Simplistic Queries: No need to overcomplicate.
Example: Directly fetching employees from the 'HR' department.
SELECT first_name, last_name FROM employees
WHERE department_id = (SELECT department_id FROM departments WHERE name = 'HR');
Performance Concerns: While CTEs can simplify readability, they may sometimes introduce performance overhead if not used judiciously.
Permanent Use Cases: If you're repeatedly using the same 'temporary table' logic across multiple SQL statements or sessions, perhaps you should consider creating a view or a permanent table.
Types of CTEs
There are three types of CTEs
Basic CTE
Writeable CTE
Recursive CTE
Let’s talk briefly about each one of them.
Basic CTE
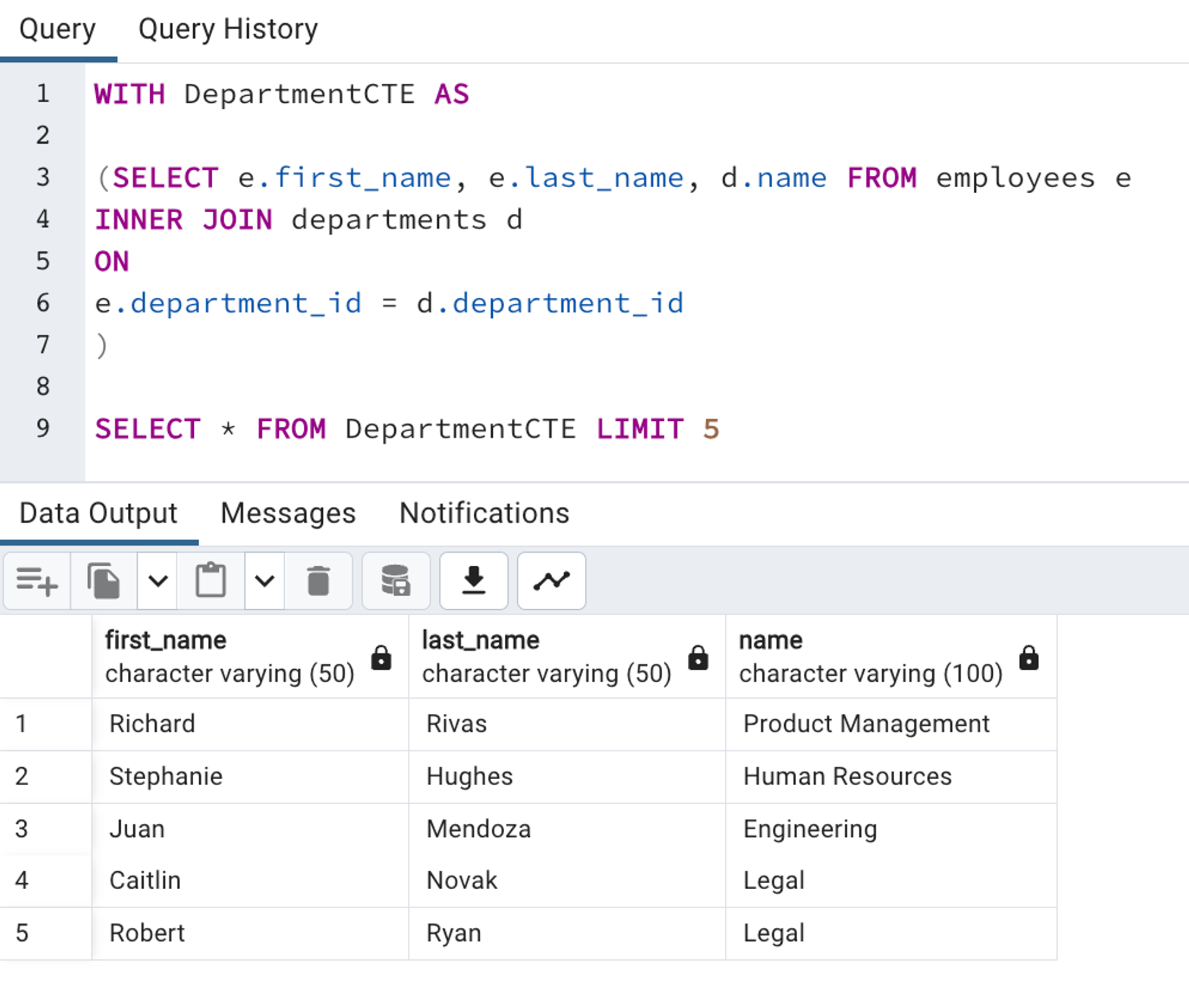
Here DepartmentCTE is the name of the CTE and if you notice the second query is querying the CTE, not the table directly.
So what is a CTE? It's a table generated by a nested query that can be queried independently.
In PostgreSQL, you can also use multiple basic CTEs together like this:
Find the code here
Writable CTE
Writable CTEs in PostgreSQL allow you to write in a CTE.
You can perform data modifications like INSERT, UPDATE, and DELETE within a CTE.
This provides a streamlined way to perform complex data manipulations and maintain the readability and organization of your queries.
The natural question is what problem does it solve and why do you care?
When you have a series of operations to perform on data before you store it or update records in a table, you might end up with a spaghetti of subqueries.
Writable CTEs enable you to structure your data transformations in a clean, step-by-step manner.
Here are some examples of when to use it —
Consider a scenario where you want to increment the salary of all employees by a certain percentage and store the result back into the compensation table.
WITH UpdatedSalaries AS (
SELECT employee_id, salary * 1.1 AS new_salary
FROM compensation
)
UPDATE compensation AS c
SET salary = us.new_salary
FROM UpdatedSalaries AS us
WHERE c.employee_id = us.employee_id;
Updating Data with Conditions
Suppose you want to update records in the employees table based on specific conditions.
WITH EligibleForPromotion AS (
SELECT e.employee_id, c.salary
FROM employees e
JOIN
compensation c
ON e.employee_id = c.employee_id
WHERE c.salary > 50000 AND department_id = 7
)
UPDATE employees
SET position_id = 7
FROM EligibleForPromotion
WHERE employees.employee_id = EligibleForPromotion.employee_id;
I know, it is tempting to use these CTEs everywhere but don’t use them everywhere.
It’s not suitable for basic single-table updates, a direct UPDATE statement is more efficient and readable.
UPDATE employees SET department_id = 4 WHERE department_id = 3;
If you're simply copying data from one table to another without any modifications, you might be better off with a direct INSERT INTO ... SELECT ... statement. Don’t use it for Bulk Inserts Without Transformation.
While writable CTEs provide structure, complex updates with a large number of records could potentially impact performance. In such cases, optimizing using other techniques might be advisable. Again, don’t use for Performance-Critical Updates.
Recursive CTE
This is a pretty advanced topic and as a beginner, you’re hardly going to use this.
You can move on to the next section, but I tried to make it as simple as possible for you to follow.
Okay, you asked for it...
Imagine you're watching a football match, and there's this irritating player who keeps passing the ball to himself, moving forward each time.
It's like he's playing a solo game of "pass and move" on the pitch.
This self-referencing action, where the player uses his previous position to determine his next move, is somewhat how Recursive CTEs work.
They reference themselves to produce a series of results.
If you have learnt about Recursion in programming it’s almost the same idea.
What are Recursive CTEs?
In PostgreSQL, a CTE (Common Table Expression) is a temporary result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. They're like temporary views for a single query. Now, when we talk about "Recursive" CTEs, we're referring to CTEs that can reference themselves!
Why Use Recursive CTEs?
Recursive CTEs are incredibly powerful when dealing with hierarchical or tree-structured data. Think of organizational charts, file systems, or even football team hierarchies where you have a head coach, assistant coaches, players, and so on.
How Do They Work?
A Recursive CTE in PostgreSQL is made up of two parts the same way as any programming language:
Base Case: This is the initial query that provides the starting point. Think of it as the first pass in our football analogy.
Recursive Case: This is the part that references the CTE itself, building on the results from the previous step.
The magic happens when PostgreSQL combines these two parts, executing the base case first and then running the recursive case repeatedly until no more rows are returned.
Example of a Recursive CTE
Let's say we have a table called football_hierarchy that represents a simple hierarchy in a football club:
id | name | role | reports_to
---|------------|---------------|-----------
1 | Alex | Head Coach | NULL
2 | Bob | Assistant | 1
3 | Charlie | Player | 2
To find the hierarchy starting from the head coach:
WITH RECURSIVE football_cte AS (
-- Base Case
SELECT id, name, role, reports_to
FROM football_hierarchy
WHERE reports_to IS NULL
UNION ALL
-- Recursive Case
SELECT f.id, f.name, f.role, f.reports_to
FROM football_hierarchy f
JOIN football_cte fc ON f.reports_to = fc.id
)
SELECT * FROM football_cte;
This will give us a list starting from the head coach down to the players.
Recursive CTEs are performance-intensive, and using this has its complications.
Read further here.
Lateral Joins
If you know about closures in JavaScript, this would be an easy concept to learn.
A lateral join is a powerful tool in PostgreSQL that enables you to reference columns from preceding tables within a subquery.
Essentially, lateral joins let you execute subqueries for each row of the outer query.
What Problem Does It Solve?
Lateral joins come to the rescue when you need to perform calculations or operations on data that is contextually related to each row.
Instead of running a separate subquery for every row, lateral joins streamline the process by correlating subqueries with their corresponding rows, resulting in more efficient queries
Where to Use It?
Employee and Manager Relationships
Imagine you have an employees table and you want to retrieve each employee's name along with their manager's name. You can utilize a lateral join to achieve this:
SELECT e1.first_name AS employee_name, e2.first_name AS manager_name
FROM employees e1
LEFT JOIN LATERAL (
SELECT first_name
FROM employees e2
WHERE e2.employee_id = e1.manager_id
) e2 ON true;
Calculations with Historical Data
Suppose you have an employee_salary_history table that tracks salary changes over time. You can use a lateral join to calculate the percentage change in salary for each employee:
--- This code just an example and won't run on our data.
SELECT e.first_name, e.last_name, s.salary_date, s.salary,
(s.salary - lag(s.salary) OVER w) / lag(s.salary) OVER w * 100 AS salary_change_pct
FROM employees e
LEFT JOIN LATERAL (
SELECT salary_date, salary
FROM employee_salary_history
WHERE employee_id = e.employee_id
ORDER BY salary_date
LIMIT 1
) s ON true
WINDOW w AS (PARTITION BY e.employee_id ORDER BY s.salary_date);
Types of Lateral Joins:
Unconditional Lateral Join: The basic form of lateral join where the subquery is always executed for each row, regardless of any condition.
Lateral Join with Correlation: A lateral join that references columns from preceding tables within the subquery. This allows dynamic computations based on the context of each row.
Lateral Join with Nested Subqueries: You can use lateral joins to chain multiple subqueries, with each subquery referring to columns from the preceding subqueries.
Where Not to Use It?
Simple Queries: For straightforward joins without complex dynamic computations, using regular joins is more appropriate.
Performance-Intensive Queries: While lateral joins enhance query flexibility, using them extensively on large datasets might impact performance. Always ensure the benefits justify any potential trade-offs.
Remember that it only works in one direction. This means your right-hand column can only draw values from your left-hand side table, not vice versa.
Interested to learn more: Read Here
This brings us to the end of this section.
TLDR;
Here are some topics that we have learned in this blog.
Common Constructions and where to use them.
CTEs - Common Table Expressions and their usage
Basic
Writable
Recursive
Lateral Joins - An analogy with JavaScript closure.
What's next
I am writing this series on PostgreSQL Distilled to help aspiring FullStack engineers learn this important technology quickly.
The next chapter is Chapter 4: FUNCTION in POSTGRESQL
Don't keep your knowledge incomplete, if you are looking for your next career jump make sure to follow me on X for updates on this series and become a better software engineer.
https://twitter.com/sagar_codes